What is image intelligence? Images are inherently data visualizations. Each digital picture is a big data set in itself, with each pixel a building block for some subset of information. An image taken by the camera of a modern smartphone contains more than 12 million pixels. If you’re looking to analyze 1,000 pictures—over one trillion data points—you will need help. That’s where Computer Vision (CV) comes in. This field uses algorithms generated by machine learning to extract from images information about objects, text, and subjective qualitative elements. In all, image intelligence can generate meaningful data on spaces, users and activities.
The simplest problem we could find
The new layout for Hub—Perkins+Will’s internal project and personnel database—required that we update the aspect ratio on all of its 2,500 employee headshots. All the pre-existing pictures had been cropped manually and without strict guidelines. How could we generate new headshots from the scattered original images, achieving consistency and uniformity of scale and position? Should we have someone manually re-crop them? Old-school. Crowd-source labor to update them, perhaps using Amazon’s Mechanical Turk marketplace? Just off-loading the burden. Or could we leverage machine intelligence to perform this task?
The machine intelligence way
To crop a photo, a human must open an image, look at it, recognize a face, and resize the area around that face with a pleasing ratio of padding. The first, second, and fourth steps are instructions that can be given to a computer at the project’s onset. So how do we get a machine to recognize a face? By using computer vision. We started with a decades-old, open-source code library known as OpenCV.
Using that code as a base, we created an algorithm that can find a face and then calculate an offset based on the face’s center. After adding a few cropping and resizing instructions, we then had a script that could process an image and return a relatively consistent, square-cropped version with a specific pixel ratio. Our results were pretty good. However, we had challenges with about 10% of the images, particularly those featuring odd lighting, strange angles, or complex hairstyles.


Refining the algorithm
Our first cropping efforts relied upon the Viola-Jones algorithm. While an excellent method for doing real-time facial and object detection, the framework—created by Paul Viola and Michael Jones—wasn’t sufficient, as we were seeking algorithms that were capable of teaching themselves how to identify “features” to track. Such algorithms can take substantial resources and skills to train, but they then can be used very flexibly afterwards.
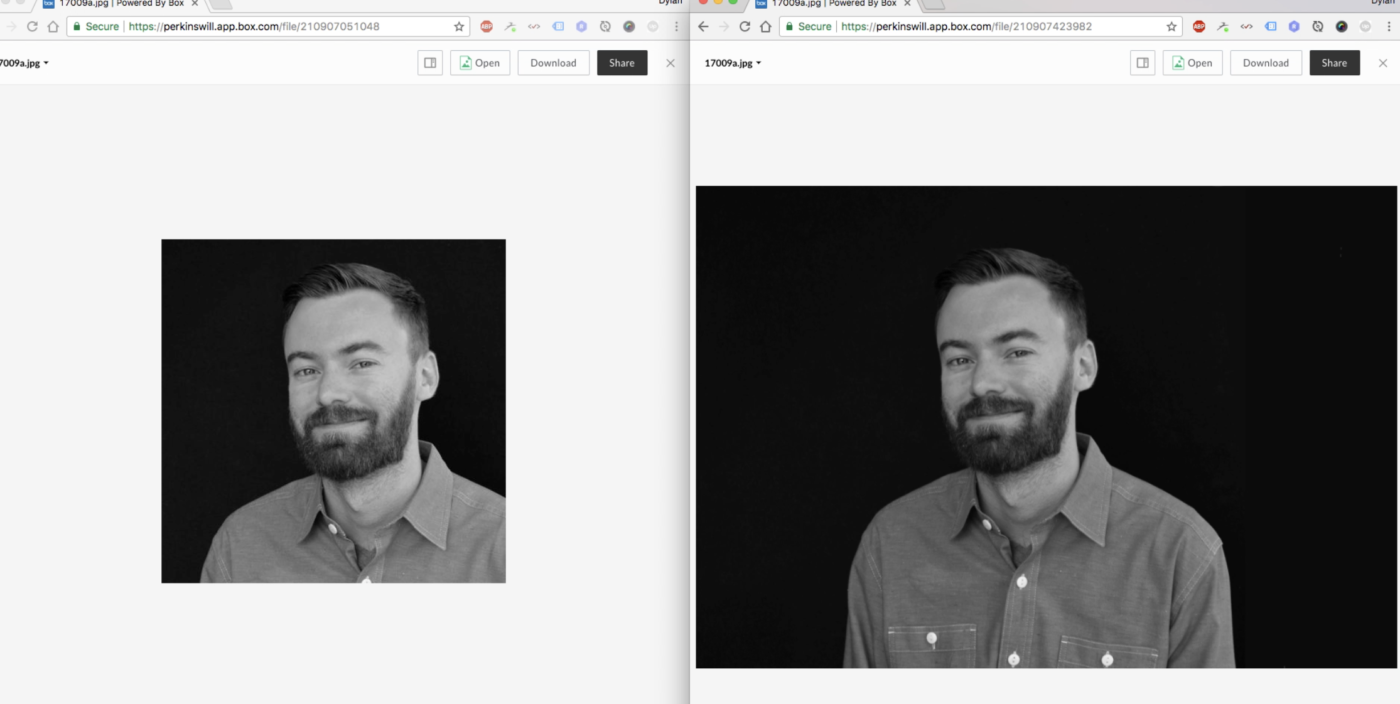
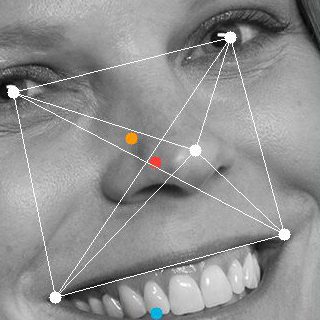
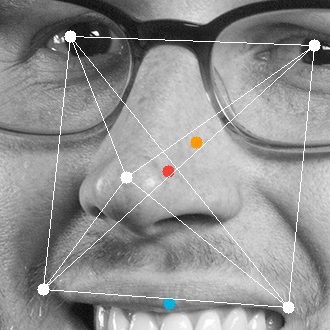
To solve our problem, we switched to Rekognition, an Amazon service that can analyze an image and detect faces and key features. (In the images above, the orange box is the facial bounding box returned by the service.) In most cases the Rekognition results were fine; they also were able to include such “landmark” features as eyes, noses, and mouth corners. These attributes are much more consistent and useful for capturing angle/rotation and even identity (more on that later). Using these features we were able to construct our own crop box around the main facial features, visualized by the red box. We used the center of this box (the red dot) to calculate an even padding around the face, with a slight offset to allow for hairstyle where needed.
Cloud integration
The final step was to integrate the cloud for a truly seamless tool. In the beginning we identified the steps the human would have to take to crop a photo, which included opening apps and issuing commands. Now that we had an application that was capable of handling the entire process via automation, why not trigger the process automatically as well?
We integrated the process directly into Box, our cloud content management system, allowing the entire operation to occur autonomously and behind the scenes. A user just needed to drag and drop an image into a folder; automatically, a new folder storing different size and aspect ratio headshots was created.
If an updated headshot was loaded, all headshots and avatars linked to that user (Hub, Skype, LinkedIn, etc.) would be formatted, replaced, and archived.

How much time does this save?
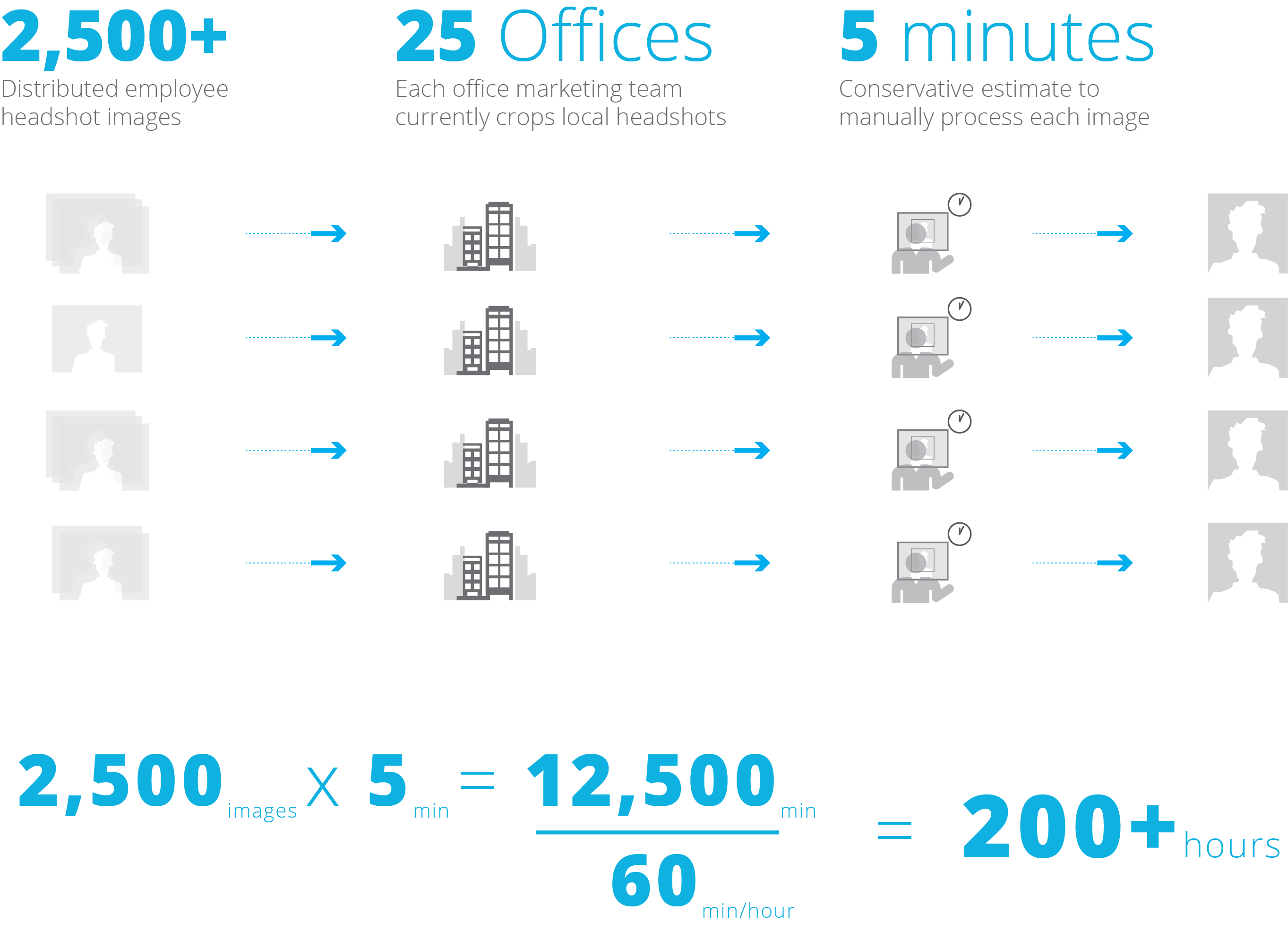
This is an excellent demonstration of how to leverage cutting-edge technology to improve our internal processes and free up time for our design experts to focus on more valuable efforts. Currently headshots are manually cropped by a marketing professional in each of our 24 offices. It is a significant effort to manually collect and process each headshot. Even if we assume a conservative estimate of five minutes per image, this process saves 24 over-qualified team members over 200 combined hours. If we add a new service or need to update headshots again in the future, the same amount of man-hours would be required. Our new method also ensures consistency, labeling accuracy, and correct placement under our file-storage protocols.
So...what else does it do?
This may not have been the coolest application of built artificial intelligence utilizing deep learning that you’ve ever seen. (Not Hotdog – mildly NSFW). However we’ve only scratched the surface. Remember the landmark features? These points unlock another world of opportunities. We can use those features to map emotions to determine if someone is smiling or where she is looking (both focus and attention). Add a half-dozen more landmark points, and you begin to create a non-image mesh that can serve as a digital fingerprint. This is how auto-tagging features on Facebook, Google, and Apple photo apps are able to identify who is in the picture. Other image classification routines can help categorize features like glasses or facial hair—and even gender and age.

Using Rekognition to track utilization
We decided to see if we could use the highly trained Rekognition facial detection algorithm to solve a common problem in the design industry: utilization tracking, which is understanding who uses a space, when it’s used, and how. For the experiment, we pointed a Raspberry Pi microcomputer with a camera at the elevator accessing our office’s public lounge. We set the camera to take a picture every five seconds and upload the image to an Amazon Web Services (AWS) S3 bucket. We specified that the upload trigger Lambda, AWS’ server-less data-processing system, to execute the Rekognition code, running the detection routine and returning the findings as a data array.
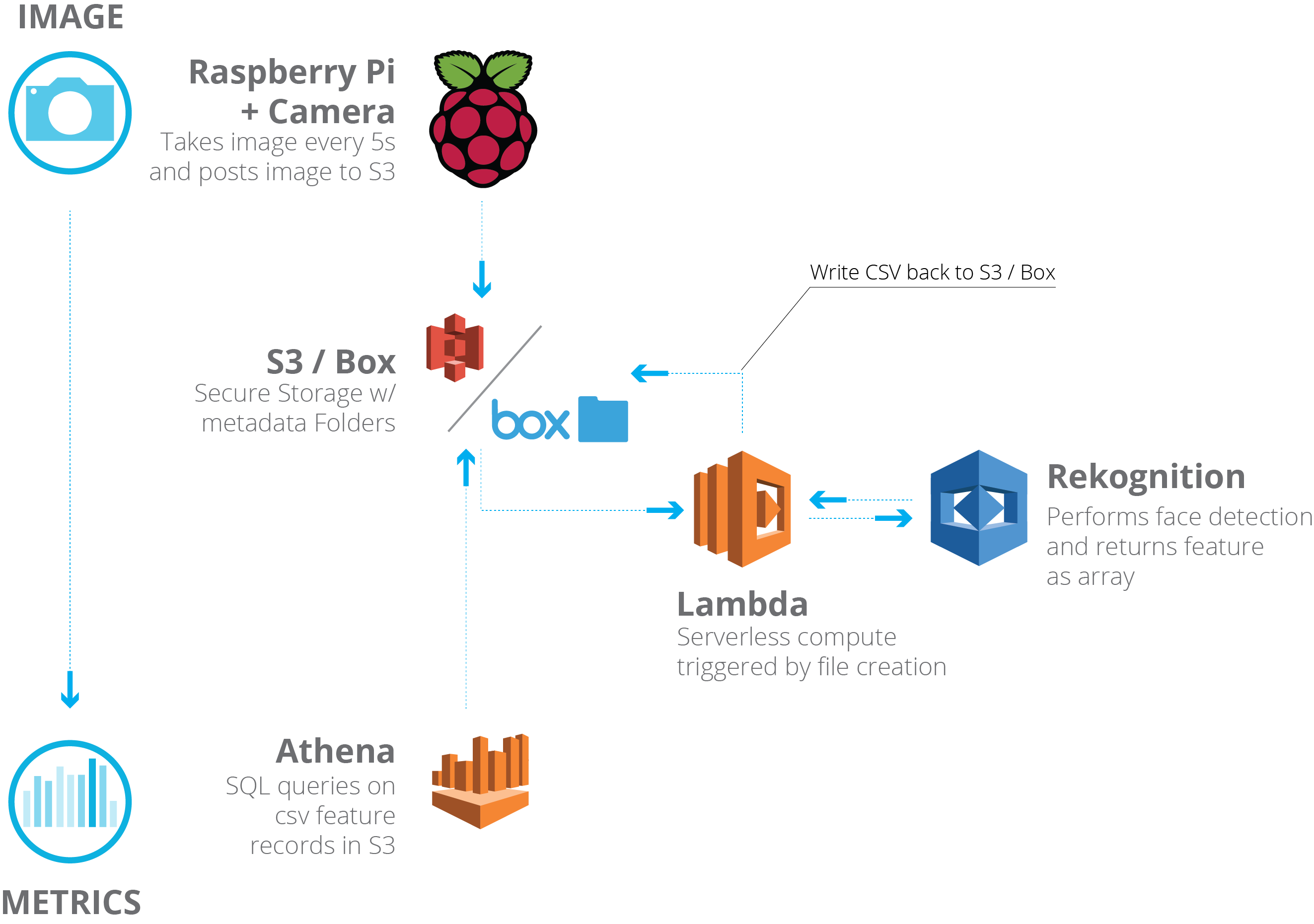
When the routine ran, it detected faces in the image. It then turned the image features into a data array of words and numbers. The original image could then be deleted. The entire process was protected via Amazon security and authentication; it was anonymous by default once the image was destroyed. We also used AWS’ Athena service to compose SQL queries to return dynamic data tables from the individual records stored in our S3 bucket. Now, we had successfully converted raw image data into a structured table of user information.
The pilot test results
We began with a quick-and-dirty pilot test, setting up the camera for an hour to measure the results. One of the best things about this method was that data is automatically time-stamped when it arrived in the S3 bucket and triggered the Rekognition API call. That means that all the routine had to do was capture an image and send it. The Rekognition service returns details if it finds a face, timestamping when the image was received. As long as we are confident that the routine was running continuously and successfully, we could assume (in theory) that we were capturing the flow and frequency of visitors to the space.
We were eager to see how the algorithm handled the various cases of multiple people, and the various angles and approaches as they entered and left. We also realized the data would be even more valuable if we could know for how long people were using the space, but saved that aspect for the next experiment.

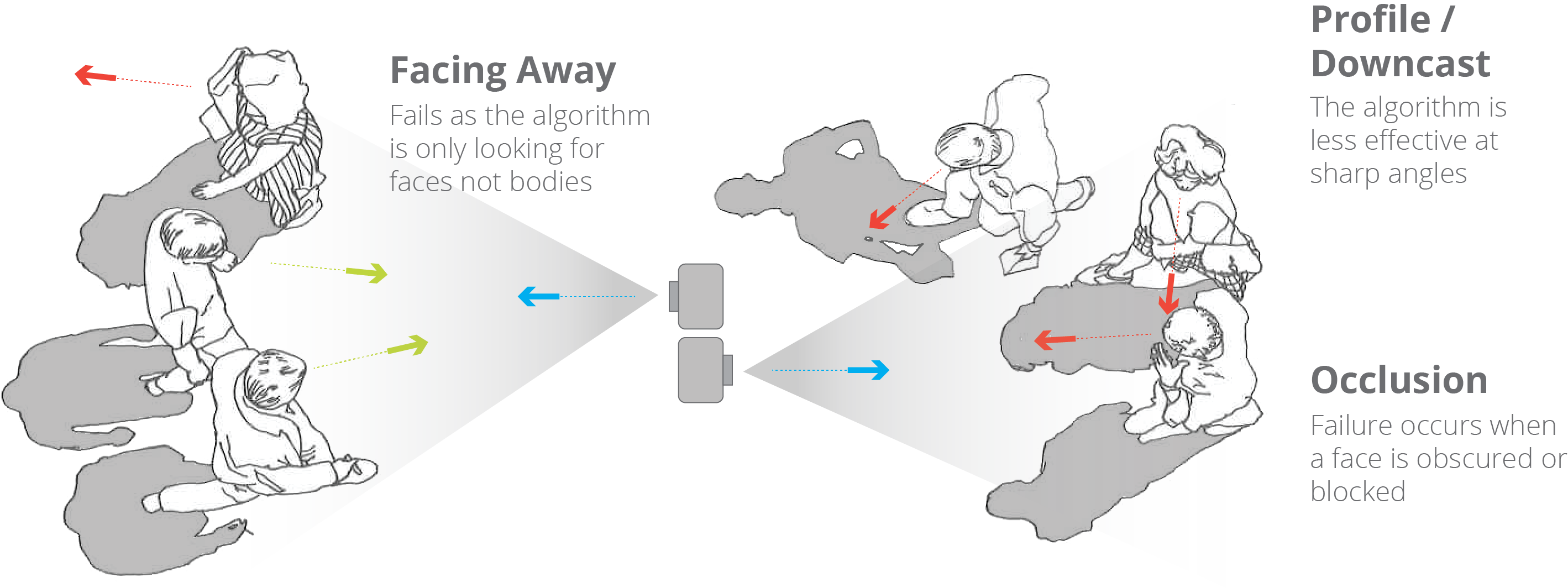
Where does our utilization experiment fail?
The set up missed or misread users when they were not facing the camera within a certain field of view. Obviously this was a serious handicap in situations where a Computer Vision (CV) algorithm should be able to detect a human person, but in this case we were only looking for faces. In addition to the angle of the face, any significant obstructions affected the algorithm’s ability to detect a person using the base Rekognition service. Here we saw a number of failures. Based on the number of samples we submitted and the return results, we saw that quite a few people were missed in this initial study.
The good news
This (admittedly small) pilot test set did not return highly accurate results. Based on the jump error rate in the chart above, it was clear that there will be times of higher and lower error based on many factors; longer testing was required to understand what the overall error rate would be using the current algorithm.
However, let’s assess the success of this first attempt. We knew we weren’t trying to capture 100% of individuals (let alone any PII – Personally Identifiable Information). Rather, we were trying to discover whether we could use this service and method to conduct relative utilization studies at scale.
The good news is that with our five-second rolling interval we could still capture people in one frame even if we lost them in others. We also know that we are likely to use this information comparatively and not for absolute counts (relative use of space A vs space B). But the best news is that that we can re-train these algorithms to identify a new feature set (bodies vs faces) rather than start from scratch.
The future potential
There are a few other techniques we can use to apply machine-trained algorithms in the pursuit of CV-based “counting.” Tools like Rekognition are in the early days of deployment, and we are actively working with AWS to explore the service’s future potential and usage scenarios.
However, what is much more interesting than simple counts of people are the different kinds of interactions that take place in a space. This is also something that a CV algorithm can be trained to recognize. We can use the results to validate that people are using spaces in the way they are intended or to understand how they are positively re-appropriating them. We even can glean insights into people’s emotional responses to a space.