One of the challenges to research and analytics today is an extreme shift in methodology and sequence due to the explosion of “Big Data.” The reality is that most problems–and most data sets–confront small to medium data. Big data might also be called data first, which is a different paradigm to the scientific method we all learned in grade school.
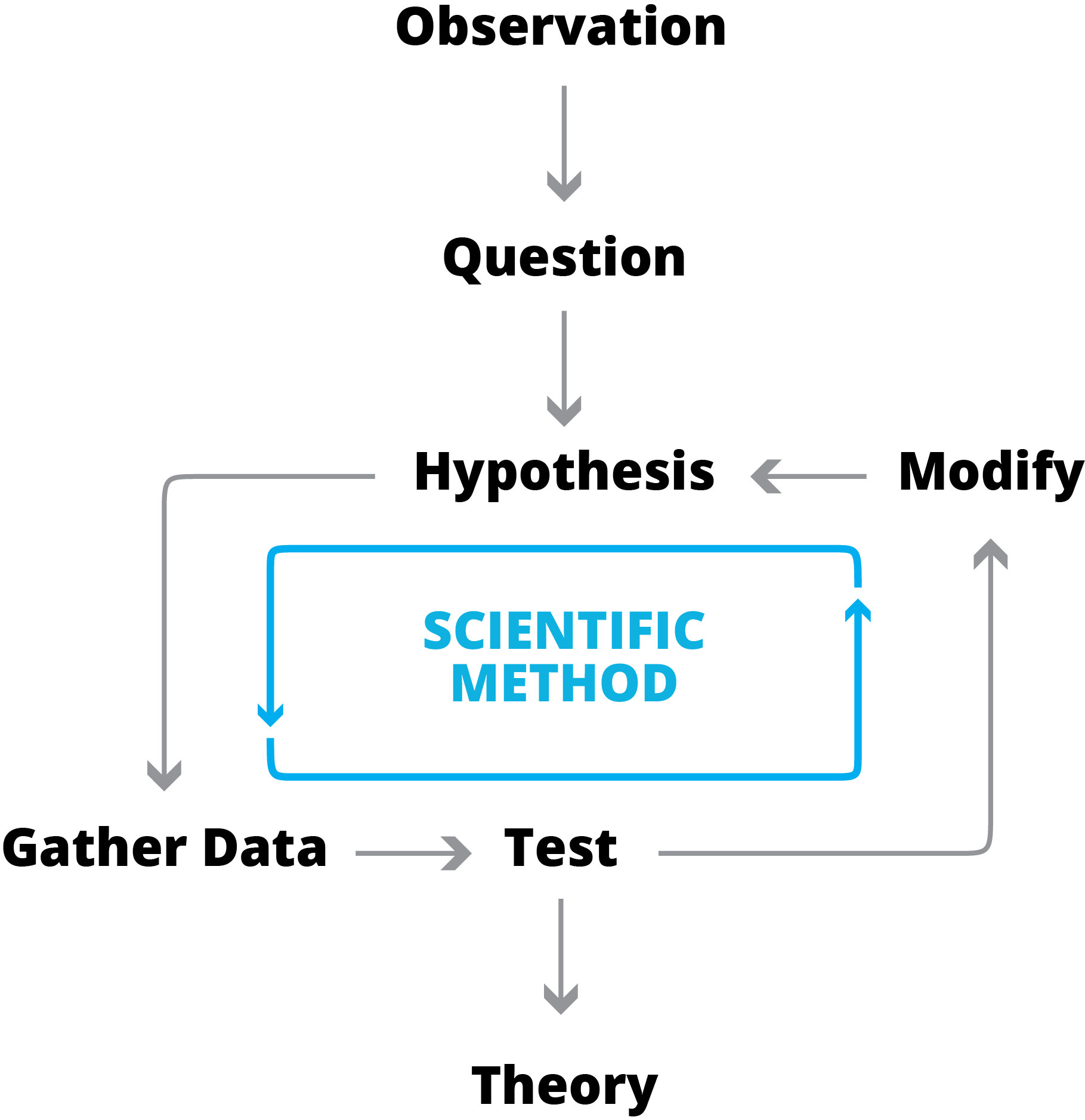
The Traditional Scientific Method
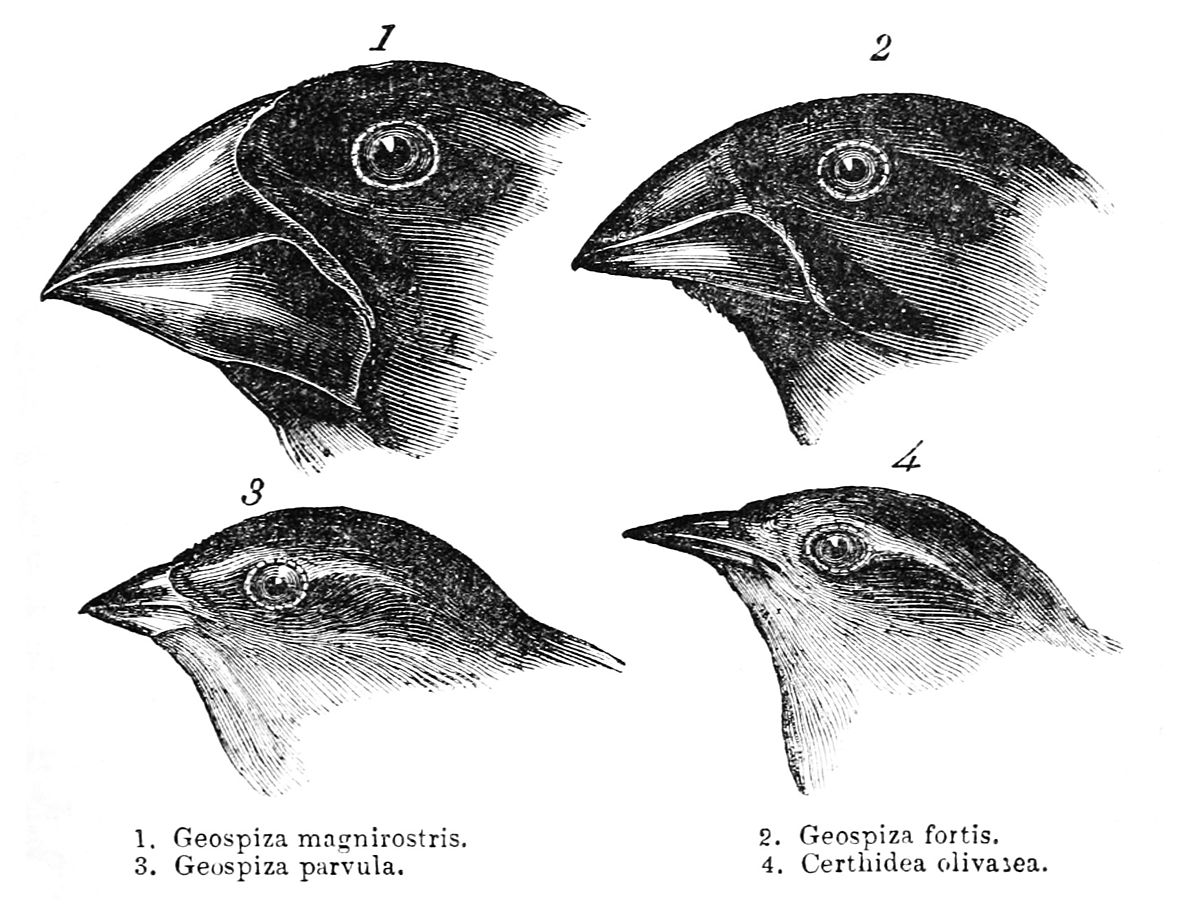
Let’s take a classic example of the scientific method at work and compare it to how we might approach the problem today. The development of Darwin’s theory of evolution and the origin of species is an excellent illustration of the traditional scientific model. It begins with an observation; in this case that different birds of a similar species have different beaks. This leads to a question which is most generally framed as “Why? [is this so]” From here you begin an iterative process which forms the core of the traditional scientific method we learn in grade school. You propose an answer to your question–a hypothesis–and proceed to collect data to support or refute said hypothesis. The results of your experiment lead you to adjust or reframe your hypotheses to align with the data that you generate. In the case of Darwin’s finches it led to the development of the theory of evolution.
What is a Data First Paradigm?
Now let us consider how this exercise would develop using a “big-data” paradigm. One of the first assumptions of a big data exercise is that you have data on hand or can easily capture data at scale using some digital process such as logging, scrubbing, sensing, etc. Once you have your dataset, you proceed to “mine” it for insights. To tackle this problem today we might rely on Google image search as our data source. By typing the word “bird” or “finch” into the search field, we can eventually return hundreds of thousands of images of birds to study.
Once we have our dataset, we can proceed with our analysis. Because the entire dataset is digital, we can use computer algorithms to examine every single image and extract “features” (see image intelligence). An algorithm can learn to identify a feature by analyzing each image over and over again with different parameters, eventually teaching itself what different parts of birds might be and where they are in each image. Eventually a library of different features and their combinations will appear by reviewing and comparing which features allow for the most consistent grouping and classification of birds into meaningful categories (with the assistance of human intelligence). At the end of this process, the study of the results might reveal that birds can be grouped into different species, and birds of the same species might have different defining characteristics (such as beaks) while still belonging together.
But wait...
You may be saying to yourself, that’s all well and good assuming you could just search for whatever you want to find on Google images and then run it through this series of processes. Of course Google image search uses computer vision algorithms itself to auto-generate the searchable tags on images, which creates a chicken-and-egg sort of conundrum. However, let us imagine that Darwin had our tools (cameras and computers) but not our services (in this case Google). Returning to the Galapagos, he could set up cameras to monitor the different islands and store the images.
While there would be more complexity, training and computation required, the same principles we outlined above would still work. And if there was a steady wifi signal, this data could be captured in real-time and streamed continuously to study the entire population of finches over time (more on this later). In either case, the entire study of birds (or species) could proceed from the acquisition of data, irrespective of a specific research question. And the same data set of images could be used to study other questions about birds, or even their environment and changes to both over time. This approach fundamentally changes the way we perform research and analysis in several significant ways.
Instead of beginning with an observation, the process begins (and eventually ends) with data.
When you start with a data set, you can either ask questions and analyze the data to see if they can be answered or (increasingly) you can analyze the data and try and build questions and answers around the findings.
Data grows
After you generate and validate findings, the output is added back to the individual data points, augmenting your data set. The next time you reach for your data to combine it in new ways, it is richer than before.
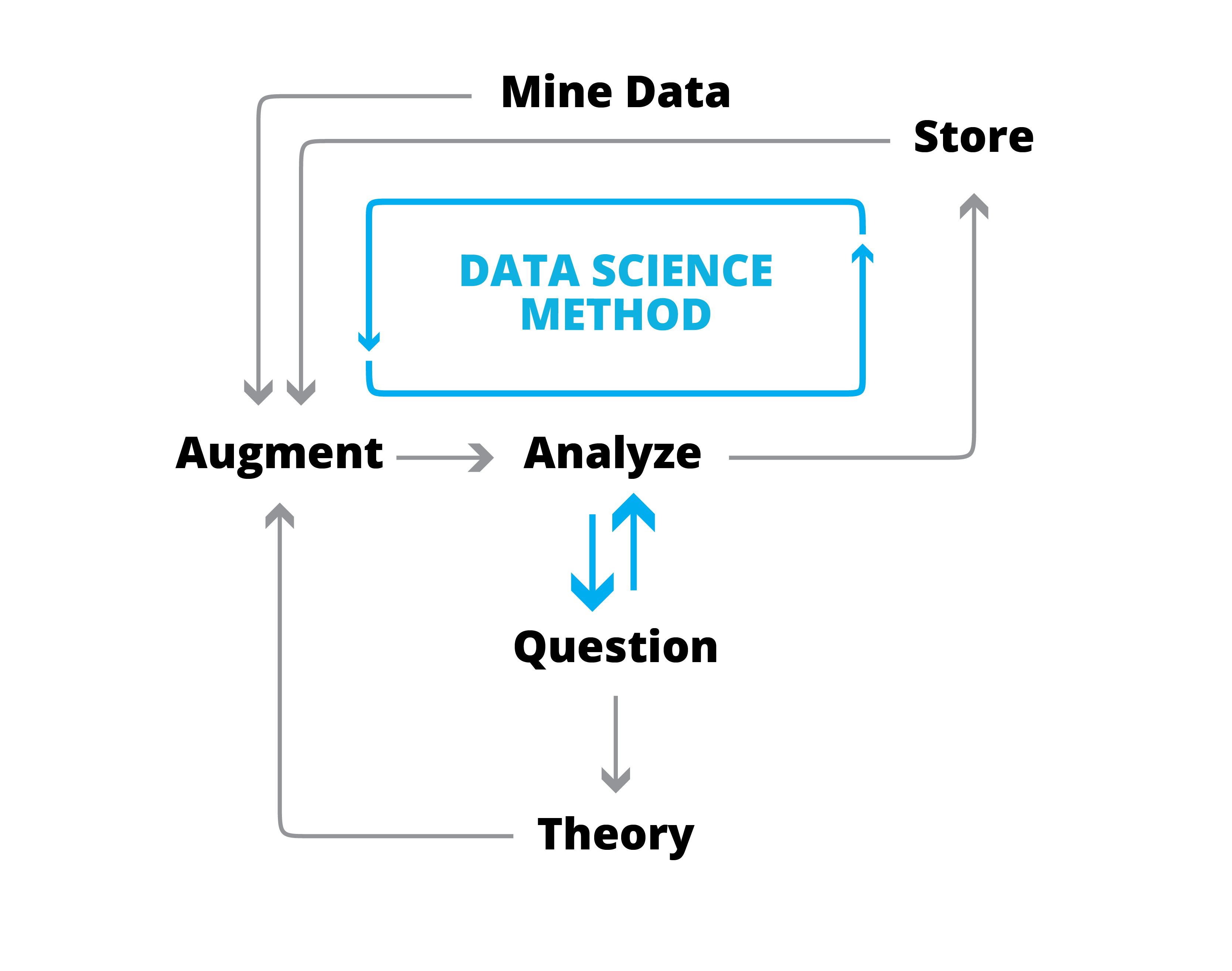
Crucial impact of a data-centric approach
One of the most critical changes to methodologies in the “big data” paradigm is the ability to study the entire population at once. If you look at the data science method vs the traditional scientific method, the acquisition and application of data is fundamentally transformed. While the traditional method seeks specific data points in the support or rejection of the hypothesis, the data first method relies entirely on data but (theoretically) ALL the data. Hypotheses and experiments are prone to all sorts of errors in sampling and unknowing (or deliberate) biases. This naturally leads to the healthy distrust of individual experiments and the slow development of theory as multiple researchers frame and study various hypotheses.
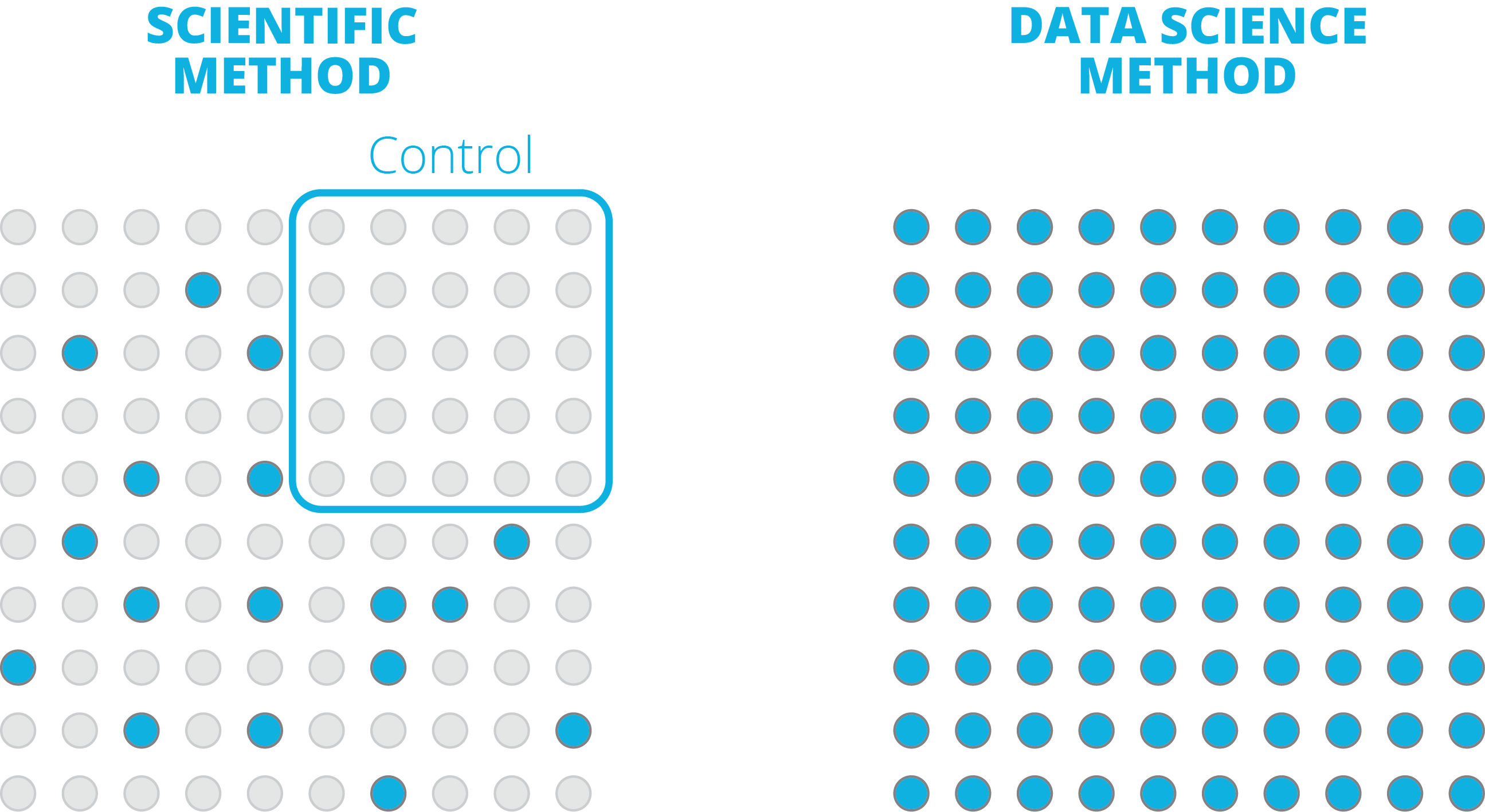
When you study the entire population in its entirety however, many of these concerns are alleviated. There is no danger of selecting a poor sample or control group. If a population is monitored continuously, there is no danger of selecting an experiment window which misses critical time periods. Of course it is not always possible to capture or generate data at that scale and plenty of research still relies on traditional scientific methods. But as technology and digital tools continue to proliferate, it is easier and easier to find and capture data on entire groups and conditions.
In our latter example of a modern-day Darwin, while the entire study may originate with a question and a hypothesis, it should still lead to a fundamentally different approach of studying the entire eco-system of an island and its feathered occupants. And instead of a specific and limited data set of bird drawings and bodies, the data set of streaming video could have other applications for ecology, climate change, etc.